今天的软件分享是 Windows 平台的 ,该软件是5ilr绿软最新搜集整理的一款网页数据抓取采集程序,该应用可以提取网页里的文本及图像,输入网址即可打开,默认使用内部浏览器,允许扩展分析,可以自动获取相似链接的列表,比如采集网址、电话、地址、邮箱、价格表等信息,该应用界面直观操作简单。
WebHarvy是一款网页数据获取应用,通过本应用您可以直接在网页上选择需求选择的资源,也可以直接将整个网页存储为HTML的格式,从而提取网页里面的所有文本以及图标内容,当您复制一个URL地址的时候,应用默认使用内部浏览器组件打开,可以显示完整的网页,随后您可以开始配合数据抓取的规则。SysNucleus WebHarvy允许扩展分析可以自动获取相似链接的列表,复制一个地址就能搜索多个网页内容,无需编写任何脚本或代码来抓取数据。您将使用WebHarvy的内置浏览器查看网页,您可以选择要单击的数据,WebHarvy自动识别网页中发生的数据方式。因此如果您需求从网页上刮取项目列表(名称,地址,电子邮件,价格等),则无需执行任何其他选项。
如果数据重复WebHarvy会自动删除它,您可以以多种格式存储从网页中提取的数据。WebHarvy Web Scraper的当前版本允许您将抓取的数据导出为Excel,XML,CSV,JSON或TSV文件,您也可以将抓取的数据导出到SQL数据库。通常网页在多个页面上显示产品列表等数据,WebHarvy可以自动抓取并从多个页面提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper就会自动从所有页面中抓取数据。
小编制录制了一个简单的基础操作供大家参考:
截图预览
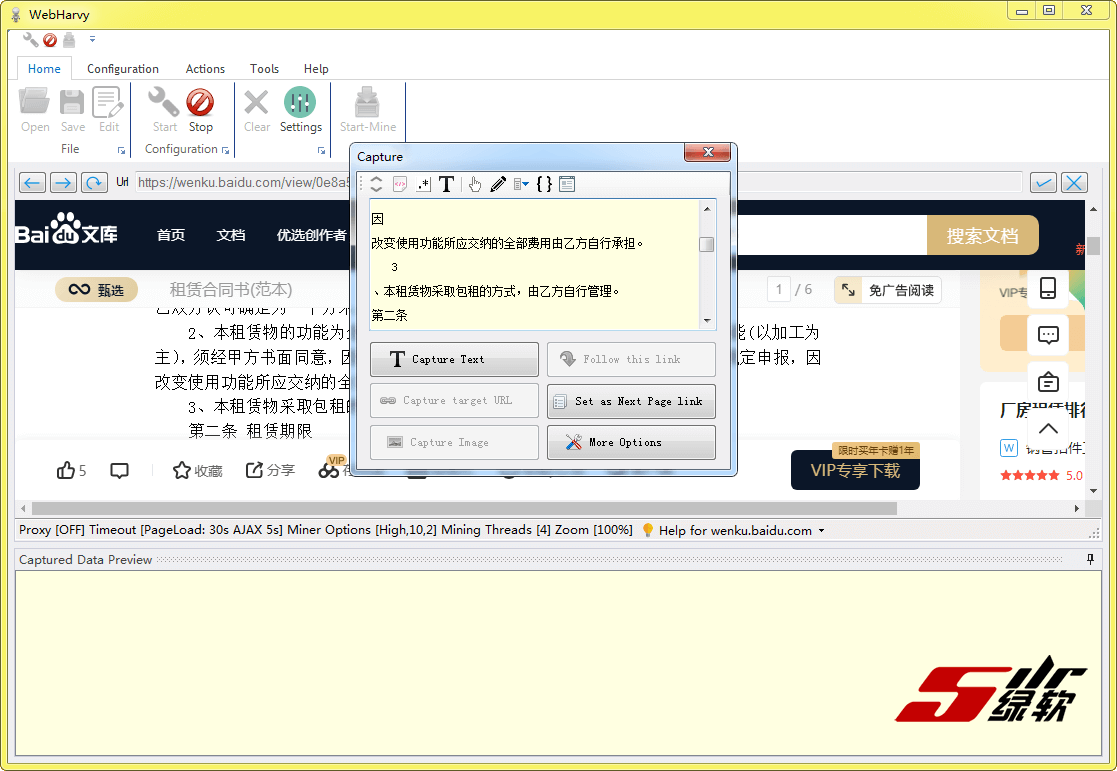
小编测试发现可以截取文库文本,但格式是错乱的。
功能特色
- 支持智能识别方式;
- 支持导出捕获的数据;
- 支持从多个页面提取;
- 直观化的操作界面;
- 支持基于关键字的提取;
- 支持提取分类;
- 支持使用正则表达式提取;
更新内容
webharvy.com
下载地址
网页数据抓取采集软件 WebHarvy 6.4.0.191 英文安装版